这个站点本身就是我的第一个 AI 实践——「用 AI 协作把想法做成能动手的东西」,它自己就是证据。比起技术栈,更值得说的是它怎么被做出来,以及过程里几个 AI 写不出来的判断。
不是手搓的:一条可复用的多 agent 流水线
本站不是逐行手写,而是用一套可复用的多 agent workflow 从 0→1 跑出来的:orchestrator 拆解目标后,依次委派「写 PRD → 设计 → 实现 → 审查 → 测试」,并在 PRD、设计、验收三处停下等我拍板。spec 是贯穿全程的唯一事实源。同一个目标,我还在 Codex 和 Claude Code 两边各跑了一版做 A/B,最后选更合意的那版作主线。我的角色不是写代码,是定义约束、在每个 gate 上做取舍、决定哪一版胜出。
一个只在自己浏览器里才暴露的 bug
最值得记的教训来自字体。最初用 Google Fonts 的 <link> 加载几款 webfont,构建全绿、CI 全过——但在我自己的浏览器里整站悄悄回退成了系统字,因为 Google Fonts 在国内被墙。再一查,审批过的设计稿用的本就是系统字,那几款 webfont 只是残留。于是定稿为「系统字 + 仅自托管 Space Mono」,打包的 woff2 从 621 个降到 6 个。沉淀成一条原则:国内项目默认自托管字体与资源,不依赖 Google CDN;而「构建全绿、在地渲染却错」这类 bug,只有在本人环境里才会暴露——这一脚 AI 替你踩不到。
趁本金小时还技术债
v1 很早就把 Astro 从 4 逐个大版本升到 7(4→5→6→7),每步都 build + 跑验收断言、独立 commit 便于回退;唯一真正的破坏点是 content collections 在 v6 的迁移。逻辑很简单:项目越早、代码越薄,技术债的本金越小;拖到集成变重,就会跨三代不敢升。
公开站只放可公开的事实
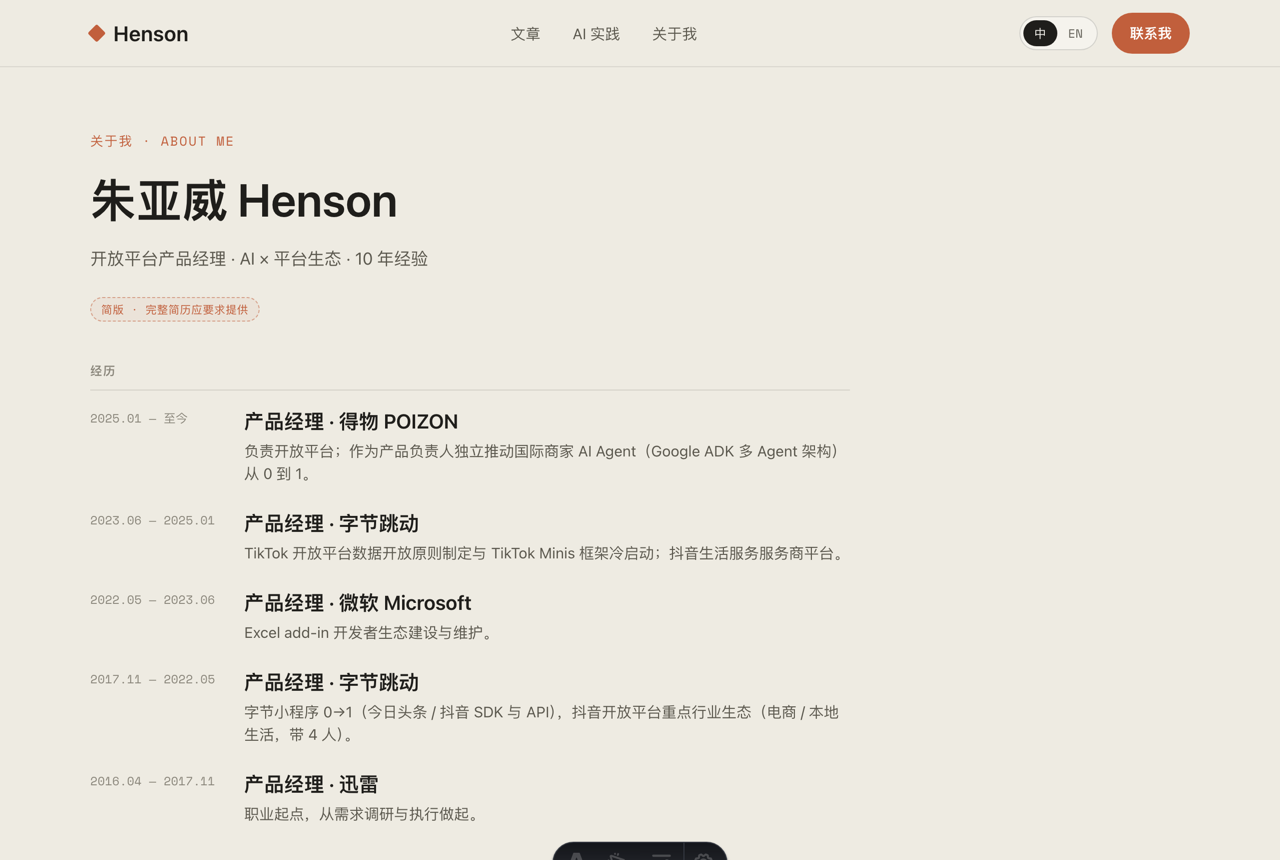
公开仓库意味着边界要硬:知识库里的薪资、跳槽策略、具体公司业绩一律不进站;hero 只用「年限 / 行业广度 / 管理 + 一线」这种不暴露雇主数据的表述。也据此主动偏离了原始设计稿——不放简历 PDF、不公开工作项目,而且把对应源文件从 repo 里删掉(公开仓库里「删源才算真正下线」)。设计稿是历史参照,真正的事实源是 spec 与代码。
这个站会一直长——你现在看到的每一次迭代(包括这条 AI 实践本身)都记在它的 git 历史里。